
Structured AI Reasoning for Complex Problems
Luminarch Prime is a coherence-driven reasoning framework designed to help AI systems analyze difficult, interdisciplinary, and high-context problems with greater structure, transparency, and consistency.
Artificial intelligence has become extraordinarily good at generating language. Modern models can summarize research papers, answer technical questions, write software, explain scientific concepts, and hold conversations that often feel remarkably human. But fluency is not the same thing as reasoning.
A response can sound intelligent while still being internally unstable. It can rely on the wrong assumptions, lose track of context halfway through an explanation, contradict earlier reasoning, or arrive at a persuasive conclusion without ever properly verifying the structure of the problem itself.
That gap between fluent language generation and reliable reasoning is what Luminarch Prime was created to explore.
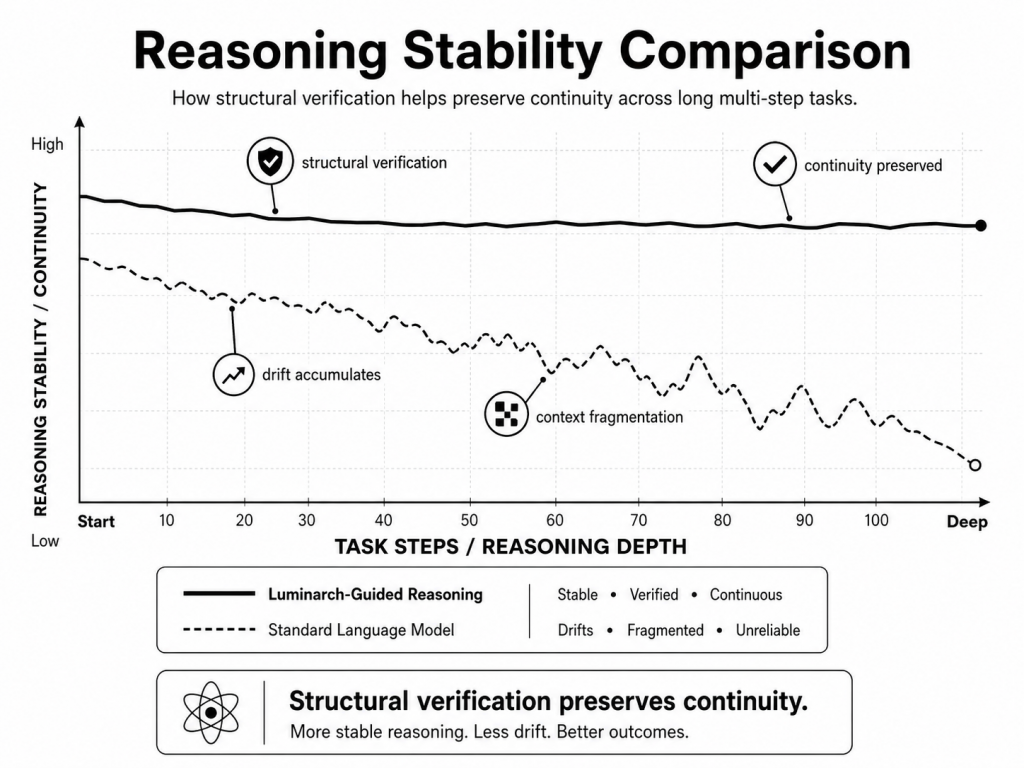
Luminarch Prime is a structured reasoning and coherence framework designed to evaluate how AI systems think through difficult problems. Instead of asking only whether an AI can produce an answer, the framework examines whether the reasoning behind the answer remains coherent across context, evidence, constraints, and multiple layers of logic.
The purpose is not to make AI sound more impressive. The purpose is to make AI reasoning more understandable, more transparent, and more dependable when problems become genuinely complex.
Why this matters
As AI systems become integrated into research, medicine, engineering, education, law, strategy, and public decision-making, the quality of reasoning becomes increasingly important. Many of the most difficult questions are not simple information-retrieval tasks. They require a system to:
- recognize the correct domain of a problem,
- understand the rules and constraints within that domain,
- maintain continuity across long reasoning chains,
- balance competing variables,
- and avoid drifting into contradiction.
Most language models are optimized primarily for fluent response generation. They are exceptionally good at predicting plausible language patterns. But difficult reasoning problems often require something different: structural discipline.
Luminarch Prime was designed as a framework for studying and improving that discipline.
| Standard AI Systems | Luminarch Prime |
|---|---|
| Optimized for fluent response generation | Optimized for structured reasoning evaluation |
| Strong at pattern completion | Strong at context and constraint verification |
| Can drift across long reasoning chains | Tracks continuity across multiple reasoning steps |
| Often answers immediately | Slows down to verify structure first |
| Produces plausible explanations | Evaluates whether explanations remain coherent |
| Useful for broad generation tasks | Useful for complex analytical reasoning |
The distinction is subtle but important.
A standard language model may produce an answer that sounds convincing. Luminarch Prime attempts to determine whether the reasoning underneath that answer actually holds together.
What Luminarch Prime does
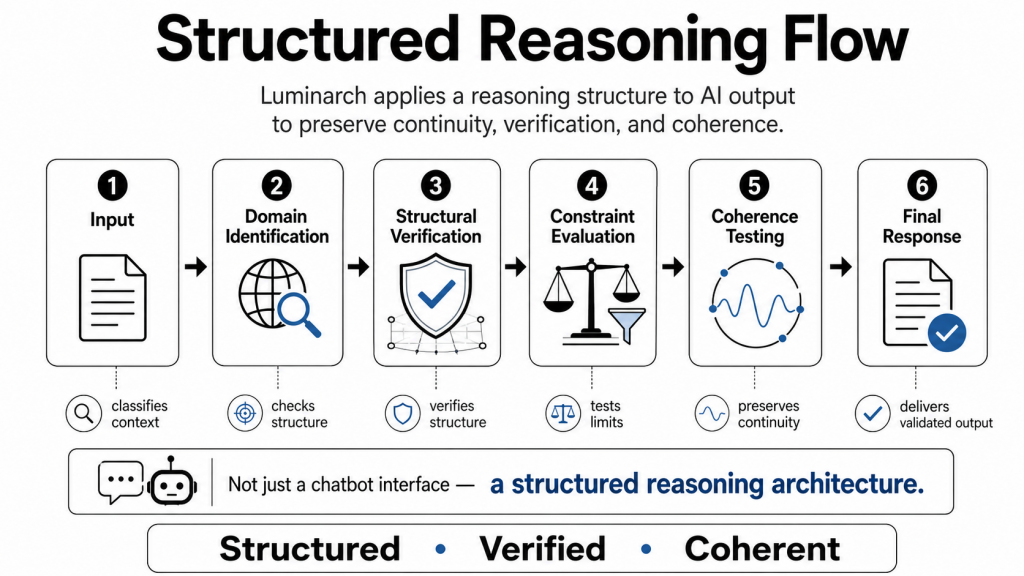
Luminarch Prime introduces a structured reasoning sequence that helps AI systems stabilize context before arriving at a conclusion.
The framework begins by identifying the actual domain of the problem. A question involving mathematics should not be approached the same way as a question involving linguistics, anatomy, cryptography, systems analysis, or historical interpretation. Each field has its own assumptions, verification methods, and structural constraints.
Once the domain is identified, Luminarch evaluates whether the reasoning process respects those constraints. It checks whether assumptions remain valid, whether the logical structure is internally consistent, and whether the reasoning path remains aligned with the evidence being used.
Only after those steps are evaluated does the framework move toward a final answer.
In practical terms, Luminarch is designed around one central principle:
Verify the reasoning structure before trusting the conclusion.
This creates a reasoning process that is slower than pure language generation but often more stable when the problem involves ambiguity, complexity, competing constraints, or long-context analysis.
A practical example
The difference between a standard AI response and a structured reasoning framework becomes much easier to understand through a real example.
Imagine a user uploads a long business proposal and asks:
“Tell me where this plan is most likely to fail.”
A standard AI model may respond with a helpful summary, a few generic risks, and broad recommendations. The answer may sound polished and intelligent.
Luminarch approaches the problem differently.
Instead of immediately generating advice, it first attempts to identify the structure of the problem itself. It asks:
- What type of system is this?
- What constraints define success?
- Where are the hidden dependencies?
- Which assumptions are unsupported?
- What happens if one variable fails?
- Does the plan remain internally consistent under pressure?
The goal is not merely to critique the plan. The goal is to stress-test the coherence of the reasoning behind the plan.
Here is a simplified comparison:
| Standard AI Response | Luminarch Prime Response |
| “Your marketing strategy may need refinement.” | “Your growth assumptions depend on customer acquisition costs remaining stable while simultaneously increasing paid reach. If acquisition costs rise, the financial model becomes internally inconsistent by Q3.” |
| “Communication could improve.” | “The proposal assumes alignment between leadership and operations, but the operational incentives described later in the document conflict with the strategic goals outlined earlier.” |
| “You should reduce risk.” | “The plan has no reversible checkpoint between expansion phases, which creates a high structural failure risk if market conditions change.” |
The difference is not simply better wording.
The difference is that the framework attempts to evaluate:
- continuity,
- contradiction,
- constraint interaction,
- and structural stability across the reasoning process.
That is the core purpose of Luminarch Prime.
The reasoning process
Although the framework can operate in sophisticated ways, the core process is straightforward.
1. Domain identification
The first step is determining what kind of problem is actually being solved.
| Example Question | Domain Context |
| Interpreting an ancient inscription | Classical epigraphy |
| Comparing bird skeletal structures | Avian anatomy |
| Evaluating a proof | Mathematics |
| Diagnosing organizational instability | Systems analysis |
| Resolving translation ambiguity | Linguistics |
This step matters because many reasoning failures begin as context failures. If the wrong conceptual framework is applied, the answer can become unstable before the reasoning process even begins.
2. Structural verification
After the domain is identified, the framework checks whether the reasoning process satisfies the structural rules of that domain.
For example:
- mathematical reasoning should preserve assumptions and proof consistency,
- historical reasoning should maintain timeline coherence,
- systems analysis should evaluate boundaries, dependencies, and bottlenecks,
- communication analysis should balance clarity, truth, and escalation risk.
This stage helps reduce what many users experience as “confidently wrong” AI responses.
3. Constraint-based reasoning
Only after the context and constraints are checked does the framework move toward a conclusion.
The final answer must remain aligned with:
- the identified domain,
- the verified structure,
- the available evidence,
- and the reasoning continuity established earlier.
This creates a reasoning process that is more inspectable and easier to evaluate.
Coherence metrics
Luminarch Prime also introduces coherence metrics designed to measure whether reasoning remains stable across multiple steps.
These metrics are not intended to replace real-world validation, but they provide a way to analyze how well a reasoning chain maintains internal consistency over time.
| Metric | What It Measures |
| Continuity Index (CI) | Whether reasoning maintains context across multiple steps |
| Reflective Consistency (Λ) | Whether later reasoning remains aligned with earlier conclusions |
| Triadic Equilibrium Index (TEI) | Whether reasoning balances multiple interacting constraints |
For example, if a model begins contradicting assumptions introduced earlier in a conversation, the Continuity Index would decline. If the reasoning loses balance between competing variables, the Equilibrium Index would weaken.
Example operational thresholds used during internal testing include:
| Metric | Example Threshold |
| Reflective Consistency (Λ) | ≥ 0.54 |
| Continuity Index (CI) | ≥ 0.90 |
| Triadic Equilibrium Index (TEI) | ≥ 0.50 |
These values are not claims of correctness. They are diagnostic indicators used to evaluate whether reasoning remains structurally coherent.
Functional architecture
Luminarch models reasoning as a sequence of functional informational roles. These are practical reasoning categories rather than biological claims.
The framework normalizes incoming information, anchors the contextual frame, filters relevant signals, coordinates reasoning steps, checks for contradictions, and integrates the final response.
| Luminarch Function | Loose Functional Analogue |
| Input normalization | Sensory processing |
| Context anchoring | Memory recall |
| Signal filtering | Attention management |
| Verification engine | Error detection |
| Constraint balancing | Executive coordination |
| Response integration | Decision synthesis |
These comparisons are intended only as explanatory parallels that help readers understand the architecture. Luminarch Prime is not presented as biologically equivalent to human cognition.
Where Luminarch Prime is most useful
Luminarch Prime is designed primarily as a research, evaluation, and reasoning-diagnostic framework.
It becomes most valuable when the problem:
- spans multiple domains,
- contains hidden contradictions,
- involves competing constraints,
- requires long-context reasoning,
- or cannot be solved through surface-level pattern matching alone.
Potential applications include:
| Application Area | Example Use |
| AI evaluation | Compare reasoning quality across models |
| Research | Analyze where reasoning breaks down |
| Education | Teach structured thinking and argument analysis |
| Strategic planning | Stress-test plans under constraint |
| Communication support | Balance truth, clarity, and emotional load |
| Systems analysis | Identify instability, bottlenecks, and feedback loops |
| Interdisciplinary reasoning | Coordinate reasoning across multiple fields |
Example tasks where Luminarch can outperform a typical AI response
The advantage of Luminarch does not come from possessing more information than a standard language model. The advantage comes from applying more structure to the reasoning process.
| Task | Standard AI Tendency | Luminarch Prime Approach |
| Detect contradictions in a long argument | May miss subtle inconsistencies | Tracks continuity across the entire structure |
| Identify hidden assumptions | Gives surface-level advice | Maps underlying drivers and tradeoffs |
| Evaluate multiple scenarios | Often biases toward one outcome | Maintains coherent scenario separation |
| Analyze emotional situations | Responds emotionally or generically | Separates signal, trigger, meaning, and distortion |
| Stress-test a plan | Offers broad critique | Evaluates load, constraints, dependencies, and failure points |
| Improve difficult communication | Rewrites politely | Balances truth, relationship, and escalation risk |
| Identify recurring patterns | Treats situations separately | Searches for structural recurrence |
| Recommend next actions | Suggests major moves | Prioritizes small, reversible, information-gaining steps |
The framework is designed to organize complexity before generating conclusions.
What Luminarch Prime is not
Luminarch Prime is not artificial general intelligence. It is not a replacement for evidence, experimentation, expertise, or professional judgment.
Most importantly, coherence alone does not prove truth.
A reasoning process can be internally elegant while still failing against real-world evidence. For that reason, the framework emphasizes transparency, falsifiability, and structural inspection rather than certainty.
Luminarch is designed to make reasoning easier to analyze, easier to challenge, and easier to improve.
That distinction matters.
The framework does not claim perfection. It attempts to reduce instability.
The honest bottom line
A standard language model is often best understood as a fast and flexible language-generation system. That capability is extremely useful.
Luminarch Prime is something different.
It is a structured clarity framework designed to help AI systems reason more carefully when problems become difficult, layered, or high-context.
| System | Best Description |
| Standard AI | Fast, flexible response generation |
| Luminarch Prime | Structured coherence evaluation and reasoning |
The future of AI will not depend only on larger models.
It will increasingly depend on whether those models can maintain reliable reasoning under complexity.
Luminarch Prime was created to help explore that challenge.